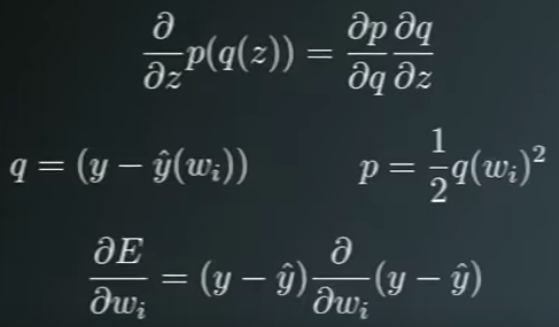Gradient of the squared error
The direction is the opposite to the gradient, the slope.





Local Minimum
Since the weights will just go where ever the gradient takes them, they can end up where the error is low, but not the lowest. These spots are called local minima. If the weights are initialized with the wrong values, gradient descent could lead the weights into a local minimum, illustrated below.
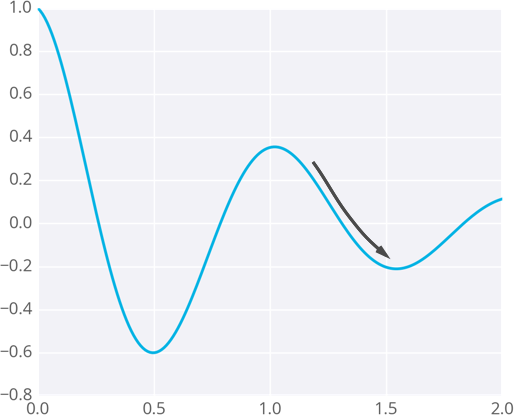
모멘텀(momentum)을 사용하면 이를 해결할 수 있다.
Batch gradient descent

Stochastic gradient descent

Mini-batch gradient descent

Gradient descent optimization algorithms
출처: An overview of gradient descent optimization algorithms
뉴튼 메소드처럼 2차 미분하는 방식은 고차원 데이터셋에 대한 계산에서 실질적(feasible)이지 않기 때문에 논의하지 않는다.
Momentum

Nesterov accelerated gradient

Adagrad의 바로 이런 방식으로 동작하는 그래디언트 기반 Optimization이다.
Chain Rule Refresher